CNNs work by accumulating sets of features at each layer. It starts of by finding edges, then shapes, then actual objects.
Layers that are deeper (closer to the input) will learn to detect simple features such as edges and color gradients, whereas higher layers will combine simple features into more complex features.
Finally, dense layers at the top of the network will combine very high level features and produce classification predictions.An important thing to understand is that higher-level features combine lower-level features as a weighted sum: activations of a preceding layer are multiplied by the following layer neuron’s weights and added, before being passed to activation nonlinearity.

CNN disadvantage
Upon training CNN with the data set of images having orientation similar to Image_TrainingDataSetType, it learns the features like ‘left eye’, ‘right eye’, ‘nose’, and so on.

When Image_TrainingDataSetType is fed to this CNN for classification, it detects the learned features in the given input. Hence, it will correctly classify it as ‘Panda’.

When Image_Deformed is fed to this CNN for classification, it detects the learned features in the given input. Hence, it will incorrectly classify it as ‘Panda’.
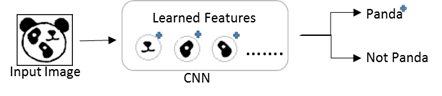
When Image_RotatedPanda is fed to this CNN for classification, it will fail to detect the learned features in the given input. Hence, it will incorrectly classify it as ‘Not Panda’.

Workaround to fix this CNN classifier to classify Image_RotatedPanda correctly is to add similar images (images of similar orientation, size, ..) in training data set and labeling them as ‘panda’. This will result in CNN learning features of more orientations of nose and eyes.
This requires more data in various poses.
The limitation of CNN is that its neurons are activated based on the chances of detecting specific feature. Neurons do not consider the properties of a feature, such as orientation, size, velocity, color and so on. Hence, it was not trained on relationships between features.
Determining the special relationship between nose and eyes in CNN requires precise location of those features in the input image. The features (nose, left eye, right eye) location information is lost at (Max)Pooling layer of CNN.
Polling Layer advantage /disadvantage
Polling Layer has the advantage of making the next layers less expensive in computing power, but also to make the network less dependent on the original positions of the features in the image.

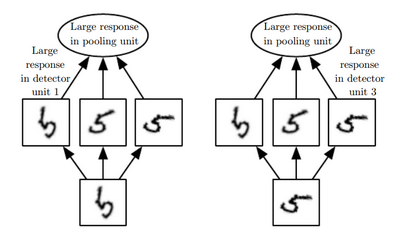
Invariant means that no matter if the order and position of the detected characters change, the output will always be the same.
This invariance also leads to triggering false positive.
The CNN can trigger the right image to match with the left image:

This was never the intention of pooling layer. What the pooling was
supposed to do is to introduce positional, orientational, proportional
invariances. But the method we use to get this uses is very crude. CNNs lose plenty of information in the pooling layers.
It is therefore assumed that the exact positions of the characteristics are not necessarily important to consider whether an object is present in the image or not.
if (2 eyes && 1 nose && 1 mouth)
{
It's a face!
}
for CNN the "face" on right is a correct face

Polling Layer loses the precise spatial relationships between higher-level parts such as a nose and a mouth. The precise spatial relationships are needed for identity recognition.
They cannot extrapolate their understanding of geometric relationships to radically new viewpoints.
In addition to being easily fooled by images with features in the wrong place a CNN is also easily confused when viewing an image in a different orientation.
CNNs cannot handle rotation at all - if they are trained on objects in one orientation, they will have trouble when the orientation is changed.

CNNs perform exceptionally great when they are classifying images which are very close to the data set. If the images have rotation, tilt or any other different orientation then CNNs have poor performance. Of course this problem can be solved by adding different variations of the same image during training.
What we needed was not invariance but equivariance. See discussion about Invariance vs. Equivariance
Equivariance makes a CNN understand the rotation or proportion change and adapt itself accordingly so that the spatial positioning inside an image is not lost.
That’s what leads us to this new architecture basic on human brain.
Brain Capsule Network
Human brain has two separate pathways, a “what” pathway and a “where” pathway (see the “two-streams hypothesis”).
Neurons in the “what” pathway respond to a particular type of stimulus regardless of where it is in the visual field. Neurons in the “where” pathway are responsible for encoding where things are. As a side note, it is hypothesized that the “where” pathway has a lower resolution then the “what” pathway.
The important thing to recognize here about the “what” pathway is that it doesn’t know where objects are without the “where” pathway telling it. If a person’s “where” pathway is damaged, they can tell if an object is present, but can’t keep track of where it is in the visual field and where it is in relation to other objects. This leads to simultanagnosia, a rare neurological condition where patients can only perceive one object at a time.
Human brain have modules called “capsules”. These capsules are particularly good at handling different types of visual stimulus and encoding things like pose (position, size, orientation), deformation, velocity, albedo, hue, texture etc.
The brain must have a mechanism for “routing” low level visual information to what it believes is the best capsule for handling it.
About routing will be later. Now let's focus how a capsule network is build.
This leads us to the recent advancement of Capsule Networks.
Capsule Neural Network - introdution
Capsule networks (CapsNets) are a hot new neural net architecture that may well have a profound impact on deep learning, in particular for computer vision.
The introduction of Capsule Networks gives us the ability to take full advantage of spatial relationship, so we can start to see things more like:
if (2 adjacent eyes && nose under eyes && mouth under nose) {
It's a face!
}
CNNs require extra components to automatically identify which object a part belongs to (e.g., this leg belongs to this sheep). CapsNets give you the hierarchy of parts for free.
This new architecture also achieves significantly better accuracy on the following data set. This data set was carefully designed to be a pure shape recognition task that shows the ability to recognize the objects even from different points of view. It beat out the state-of-the-art CNN, reducing the number of errors by 45%.

The reconstructions show that CapsNet is able to segment the image into the two original digits. Since this segmentation is not at pixel level authors observe that the model is able to deal correctly with the overlaps:

How CapsNet works
With CapsNets, detailed pose information (such as precise object position, rotation, thickness, skew, size, and so on) is preserved throughout the network, rather than lost and later recovered.
Small changes to the inputs result in small changes to the outputs—information is preserved. This is called "equivariance."

How CapsNet is build
CapsNet is composed of capsules rather than neurons.


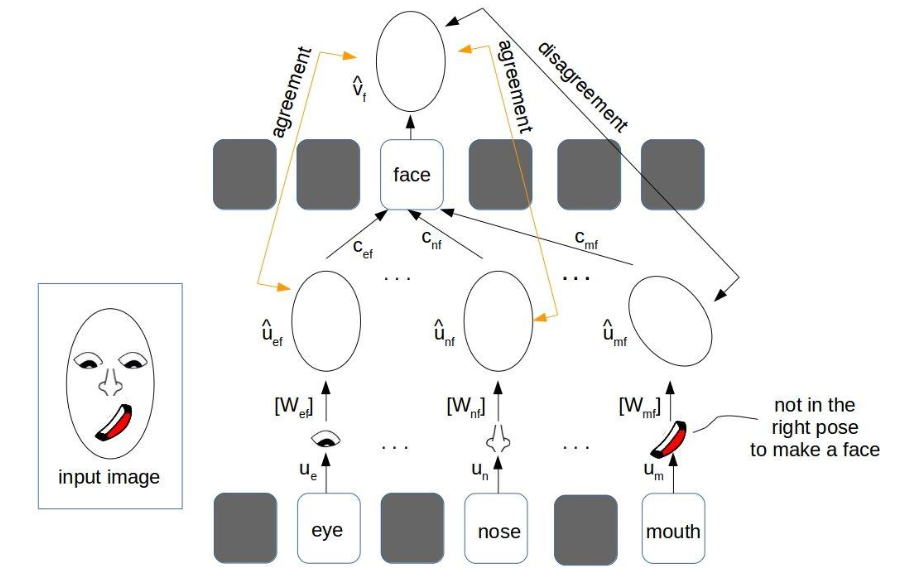
Let analize this schema for face (eyes, nouse, mouth):

- Let u1, u2, u3 be the output vectors coming from capsules of the layer below.
These vectors then are multiplied by corresponding weight matrices W (learned during training) that encode important spatial and other relationships between lower level features (eyes, mouth and nose) and higher level feature (face). - We get the predicted position of the higher level feature, where the face should be according to the detected position of the eyes:

Wij is a weight matrix (learned during training) between each ui. This Wij parameters models a “part-whole” relationship between the lower and higher level entities.
example:

If these 3 predictions of lower level features point at the same position and state of the face, then it must be a face there. - Then we compute a weighted sum sj with weights cij, coupling coefficient trained by dynamic routing (discussed next):
 cij: which feature 'j' does feature 'i' think it is a part of.
cij: which feature 'j' does feature 'i' think it is a part of.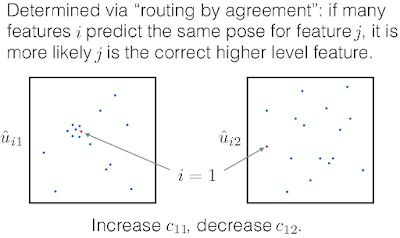
- We apply a squashing function to scale the vector between 0 and unit
length: It shrinks small vectors to zero and long vectors to unit vectors.
It shrinks small vectors to zero and long vectors to unit vectors.
Therefore the likelihood of each capsule is bounded between 0 and 1.


---------------------
A capsule is a small group of neurons that learns to detect a particular object within a given region of the image.
Like the neurons, we might have multiple levels of capsules. Then outputs of the last level of capsules could be the input to the current level.
Let us assume now we have two output vectors from the last level v1 and v2 (as input to next capsule), then we do some computation in the capsule, and generate our output v :

In CapsNet you would add more layers inside a single layer. Or in other words nest a neural layer inside another. As a result, CapsNets can use the same simple and consistent architecture across different vision tasks. So in a regular neural network you add capsule layers.
This is example of CapsNet architecture.
Encoder:
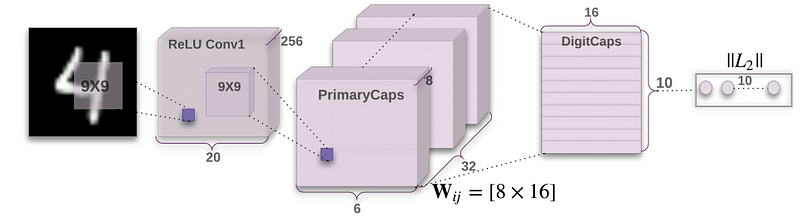
Encoder takes as a input image with size 28x28x1 and learns to encode it into a 16-dimensional vector of instantiation parameters for 10 classes. The output of the network during prediction is a 10-dimensional vectors of lengths of DigitCaps’ outputs.
Decoder:
Decoder takes a 16-dimensional vector from the correct DigitCap and learns to decode it into an image of a digit.
Decoder is used as a regularizer, it takes the output of the correct DigitCap as input and learns to recreate an 28 by 28 pixels image.
Decoder forces capsules to learn features that are useful for reconstructing the original image.

FC1: Input: 16x10 .Output: 512. Number of parameters: 82432.
FC2: Input: 512. Output: 1024. Number of parameters: 525312.
FC3: Input: 1024. Output: 784 (gives back a 28x28 decoded image). Number of parameters: 803600.
Total number of parameters in the network: 8238608.
Each output of the lower level gets weighted and directed into each neuron of the fully connected layer as input. For first layer there are 16x10 inputs that are all directed to each of the 512 neurons of this layer. Therefore, there are (16x10 + 1)x512 trainable parameters.
Articles about this CapsNet architecture:
- https://medium.freecodecamp.org/understanding-capsule-networks-ais-alluring-new-architecture-bdb228173ddc
- https://medium.com/@pechyonkin/part-iv-capsnet-architecture-6a64422f7dce
Convolutional layer
Take input image with size 28x28x1.
Extract some extremely basic features from the input image, like edges or curvesby using of 256 filter with size 9x9x1.
Outpuy is a 256 features maps with size 20x20:

After convolution layer we have main capsule layer called Primary Capsule Layer.
Primary capsules layer
Each primary capsules receives a small region of the image as input (called its receptive field), and it tries to detect the presence and pose of a particular pattern, for example a rectangle.
Starts off as a normal convolution layer but our filter have size 9x9x256.
Now we are looking for slightly more complex shapes from the edges we found earlier.
We move filter with stride=2 so the output will have size 6x6 but instead of 256 layer we will have 32 decks with 8 cards per each deck. We can call this deck a “capsule layer” so we have 36 “capsules”.


That means each capsule has an array(card) of 8 values. This array we can call a “vector”.

With a
single pixel, we could only store the confidence of whether or not we
found an edge in that spot. The higher the number, the higher the
confidence.
With a capsule we can store 8 values (as a vecttor) per location! That gives us the opportunity to store more information (position, size, orientation, deformation, velocity, albedo, hue, texture, and so on).In reality it’s not really feasible (or at least easy) to visualize the vectors like above, because these vectors are 8 dimensional.
Like a traditional 2D or 3D vector, this vector has an angle and a length. The length describes the probability, and the angle describes the instantiation parameters.

Since we have all this extra information in a capsule, the idea is that we should be able to recreate the image from them.
With a capsule network, we have something called a “reconstruction.” A reconstruction takes the vector we created and tries to recreate the original input image, given only this vector. We then grade the model based on how close the reconstruction matches the original image.
Squashing
After we have our capsules, we are going to perform another non-linearity function on it (like ReLU), but this time the equation is a bit more involved. The function scales the values of the vector so that only the length of the vector changes, not the angle. This way we can make the vector between 0 and 1 so it’s an actual probability.

This is what lengths of the capsule vectors look like after squashing. At this point it’s almost impossible to guess what each capsule is looking for.
Routing by Agreement
The next step is to decide what information to send to the next level.
In traditional networks, we would probably do something like “max pooling.”
However, with capsule networks we are going to do something called routing by agreement.
Each capsule tries to predict the next layer’s activations based on itself:

https://hep-ai.org/slides/2017-12-12.pdf
DigitCaps Layer - prediction
The capsule’s predictions for each class are made by multiplying it’s vector by a matrix of weights for each class that we are trying to predict.
Our prediction is a 16 degree vector (this size it’s an arbitrary choice):

Remember, from our example, that we have 32 capsule layers (grouped in 8 layers), and each capsule layer has 36 capsules (6x6).
That means we have a total of 1152 capsules. You will end up with a list of 11520 predictions (a total of 1152(predictions)*10(classes) = 11520 weight matrices Wij).
Each prediction is a matrix multiplication between the capsule vector and this weight matrix:

After agreement, we end up with ten 16 dimensional vectors, one vector for each class. This matrix is our final prediction.


Capsules encode probability of detection of a feature as the length of their output vector. And the state of the detected feature is encoded as the direction in which that vector points to (“instantiation parameters”). So when detected feature moves around the image or its state somehow changes, the probability still stays the same (length of vector does not change), but its orientation changes.
It outputs a vector whose length represents the estimated probability that the object is present, and whose orientation encodes the object's pose parameters.
If the object is changed slightly then the capsule will output a vector of the same length, but oriented slightly differently. Thus, capsules are equivariant.
--------------------------------------------
Dynamic Routing Between Capsules
In the "Routing Capsule Layer" we use an algorithm called "Routing by Agreement". In this example, the shape of the combination of a rectangle and a triangle will be either a house or a boat.
For the shape of the boat, a strong arrow is drawn in the Routing Capsule Layer and the recognition priority of the image becomes high:

Capsules at one level make predictions, via transformation matrices, for higher-level capsules. When multiple predictions agree, a higher level capsule becomes active. This process is described as dynamic routing, which I will talk about in more detail now.
Much like feature maps in regular CNNs, each capsule is responsible for finding some specific object/shape in the image.
The length of each capsule vector represents the probability of the entity being present at the specific location in the image and the angle of the capsule vectors encodes other properties of the objects such as the rotation angle, skew, thickness, size, etc.

In bottom example two capsules scan the image for rectangles (black vectors) and triangle (blue vectors) shapes. There are 50 capsules and the capsule in the place where the object actually exists increases. This capsule is called "The basic layer of the capsule".

The orientation of triangular and rectangular objects is represented by two vectors, each in a capsule. In other words, rectangles and triangles exist in the position of this large arrow, and by arranging the figures in the same direction, it becomes like a boat.

Much like a regular neural network, a CapsNet is organized in multiple layers.
The capsules in the lowest layer are called primary capsules and capsules in higher layers called routing capsules:

In addition, paying attention to the relationship between the rectangle and the triangular capsules, the top layer also includes a "Routing Capsule Layer" that connects multiple capsules and detects complex objects. In this example, let's consider an above example of recognizing "boat" and "house" images that are a combination of a triangle and a rectangle.
Recent paper introduces an iterative routing-by-agreement mechanism according to which a lower-level capsule prefers to send its output to higher level capsules whose activity vectors have a big scalar product with the prediction coming from the lower-level capsule. This dynamic routing
mechanism ensures that the output of the capsule gets sent to an appropriate parent in the layer above.
Dynamic routing can be viewed as a parallel attention mechanism that allows each capsule at one level to attend to some active capsules at the level below and to ignore others.
- https://hackernoon.com/uncovering-the-intuition-behind-capsule-networks-and-inverse-graphics-part-i-7412d121798d
- https://jhui.github.io/2017/11/03/Dynamic-Routing-Between-Capsules/
- https://www.kaggle.com/fizzbuzz/beginner-s-guide-to-capsule-networks
- https://dasayan05.github.io/blog/jekyll/update/2017/11/26/capsnet-architecture-for-MNIST.html
- http://brandonlmorris.com/2017/11/16/dynamic-routing-between-capsules/
- http://www.machinelearningtutorial.net/2018/01/11/dynamic-routing-between-capsules-a-novel-architecture-for-convolutional-neural-networks/
- https://www.youtube.com/watch?v=wC0rhjvst8I
- https://ireneli.eu/2018/01/23/deep-learning-16-understanding-capsule-nets/
- https://medium.com/@mike_ross/a-visual-representation-of-capsule-network-computations-83767d79e737
- https://blog.acolyer.org/2017/11/14/matrix-capsules-with-em-routing/
- https://www.youtube.com/watch?v=akq6PNnkKY8
- https://www.youtube.com/watch?v=_YT_8CT2w_Q
- https://www.youtube.com/watch?v=wC0rhjvst8I
- https://www.kaggle.com/fizzbuzz/beginner-s-guide-to-capsule-networks
- https://www.slideshare.net/charlesmartin141/capsule-networks-84754653
- http://www.machinelearningtutorial.net/2018/01/11/dynamic-routing-between-capsules-a-novel-architecture-for-convolutional-neural-networks/
- https://www.youtube.com/watch?v=wC0rhjvst8I

Summary
CapsNet is a brilliant idea, certainly, but we will have to wait for Benchmarks more consistent than MNIST to really make an idea. I am thinking of Imagenet among others.
Despite all their qualities, CapsNets are still far from perfect. Firstly, for now they don't perform as well as CNNs on larger images such as CIFAR10 or ImageNet. Moreover, they are computationally intensive, and they cannot detect two objects of the same type when they are too close to each other (this is called the "crowding problem," and it has been shown that humans have it, too). But the key ideas are extremely promising, and it seems likely that they just need a few tweaks to reach their full potential.
Sources codes:
- https://github.com/bourdakos1/CapsNet-Visualization
- https://github.com/naturomics/CapsNet-Tensorflow
- https://github.com/bourdakos1/capsule-networks
- https://github.com/llSourcell/capsule_networks
- https://github.com/XifengGuo/CapsNet-Keras
- https://github.com/ageron/handson-ml/blob/master/extra_capsnets.ipynb
- https://github.com/soskek/dynamic_routing_between_capsules
- https://www.slideshare.net/aureliengeron/how-to-implement-capsnets-using-tensorflow
- https://www.kaggle.com/kmader/capsulenet-on-mnist
Papers:
- https://arxiv.org/pdf/1710.09829v1.pdf
- http://www.cs.toronto.edu/~fritz/absps/transauto6.pdf
- https://papers.nips.cc/paper/6975-dynamic-routing-between-capsules.pdf
- https://openreview.net/pdf?id=HJWLfGWRb
Video:
- https://www.youtube.com/watch?v=rTawFwUvnLE
- https://www.youtube.com/watch?v=pPN8d0E3900
- https://www.youtube.com/watch?v=_YT_8CT2w_Q
- https://www.youtube.com/watch?v=wC0rhjvst8I
- https://www.youtube.com/watch?v=YqazfBLLV4U
Articles:
- https://github.com/aisummary/awesome-capsule-networks
- http://sailab.diism.unisi.it/wp-content/uploads/2018/02/Capsule-Networks.pdf
- https://hep-ai.org/slides/2017-12-12.pdf
- https://kndrck.co/posts/capsule_networks_explained/
- http://www.machinelearningtutorial.net/2018/01/11/dynamic-routing-between-capsules-a-novel-architecture-for-convolutional-neural-networks/
- http://moreisdifferent.com/2017/09/hinton-whats-wrong-with-CNNs
- http://www.cs.toronto.edu/~hinton/IPAM5.pdf
- https://www.slideshare.net/thinkingfactory/pr12-capsule-networks-jaejun-yoo
- https://www.saama.com/blog/capsule-networks-limitations-cnns/
- https://www.oreilly.com/ideas/introducing-capsule-networks
- http://brandonlmorris.com/2017/11/16/dynamic-routing-between-capsules/
- https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/
- https://www.edureka.co/blog/capsule-networks/
- https://dasayan05.github.io/blog/jekyll/update/2017/11/26/capsnet-architecture-for-MNIST.html
- https://medium.com/machine-learning-bites/capsule-networks-b94a2182be56
- https://hackernoon.com/uncovering-the-intuition-behind-capsule-networks-and-inverse-graphics-part-i-7412d121798d
- https://jhui.github.io/2017/11/03/Dynamic-Routing-Between-Capsules/
- https://www.slideshare.net/aureliengeron/introduction-to-capsule-networks-capsnets
- https://www.kaggle.com/fizzbuzz/beginner-s-guide-to-capsule-networks
- https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b
- https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-ii-how-capsules-work-153b6ade9f66
- https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-iii-dynamic-routing-between-capsules-349f6d30418
- https://medium.com/@pechyonkin/part-iv-capsnet-architecture-6a64422f7dce
Inne:
- https://medium.com/syntropy-ai/how-do-humans-recognise-objects-from-different-angles-an-explanation-of-one-shot-learning-71887ab2e5b4
- https://www.semanticscholar.org/paper/Deformable-Convolutional-Networks-Dai-Qi/2f0c30d6970da9ee9cf957350d9fa1025a1becb4/read
- https://www.arxiv-vanity.com/papers/1804.00538/
Ready:
- https://hackernoon.com/capsule-networks-are-shaking-up-ai-heres-how-to-use-them-c233a0971952
- https://hackernoon.com/what-is-a-capsnet-or-capsule-network-2bfbe48769cc
- https://becominghuman.ai/understand-and-apply-capsnet-on-traffic-sign-classification-a592e2d4a4ea
- https://becominghuman.ai/understanding-capsnet-part-1-e274943a018d
- https://medium.freecodecamp.org/understanding-capsule-networks-ais-alluring-new-architecture-bdb228173ddc
To check new way:
- https://bigsnarf.wordpress.com/2017/01/27/cnn-image-rotationinvariance/
- https://www.semanticscholar.org/paper/TI-POOLING%3A-Transformation-Invariant-Pooling-for-in-Laptev-Savinov/049a5a81bd664c27a6f5c973f253c7664463d13b
Harmonic network:
Thank you :)
OdpowiedzUsuń